
Real estate data mining is defined as the process of extracting actionable patterns, trends, and relationships from large property datasets to drive smarter investment and valuation decisions. The industry term for this practice is knowledge discovery in databases (KDD), though real estate professionals use “data mining” as the working shorthand. Understanding this discipline separates investors who guess from those who know. Platforms like Idealista and Fotocasa, along with recent MDPI research from 2026, have pushed the field forward significantly. If you work in acquisitions, wholesaling, or property valuation, this guide gives you the practical framework to use it.
What is real estate data mining and why does it matter?
Real estate data mining extracts patterns, trends, and relationships from large property datasets for investment and valuation decisions. It analyzes property prices, rental trends, transaction history, and neighborhood demographics through statistical and algorithmic methods. The result is intelligence you can act on, not just spreadsheets you scroll through.
One distinction worth making early: data mining differs from analytics in a fundamental way. Mining is exploratory. It uncovers hidden relationships you did not know to look for. Analytics interprets data you already have. Both matter, but mining is what gives you the edge before the market moves.

For real estate investors and wholesalers, this matters most when you are building lead lists from distressed property data, foreclosure filings, probate records, or tax delinquent databases. Mining those datasets reveals which neighborhoods have the highest concentration of motivated sellers, which property types are most likely to close, and which price ranges carry the most negotiating room. That is not a small advantage. It is the difference between cold calling blind and calling with a plan.
What types of data and sources are used in real estate data mining?
The raw material of real estate data mining falls into two categories: structured and unstructured data. Knowing the difference shapes how you collect, clean, and analyze it.
Structured data includes:
- Transaction prices and historical sales records
- Rental rates and vacancy trends
- Property features: square footage, bedroom count, lot size, year built
- Tax assessments and lien records
- Demographic data: income levels, population density, household size
Unstructured data includes:
- Listing descriptions and agent notes
- Property photos and floor plan images
- PDF documents such as title reports and inspection records
- Social media mentions and neighborhood sentiment
Automated data collection from listing platforms using robotic process automation (RPA) and web scraping enables large-scale, up-to-date datasets. Platforms like Idealista and Fotocasa supply listing price, property features, description, and location at scale. Public records databases, county assessor portals, and MLS feeds round out the picture.
The real challenge is aggregation. When you pull data from five sources, the same property often appears with different addresses, different square footage figures, and conflicting ownership records. Standardizing, de-duplicating, and reconciling those records into a single reliable profile is where most real estate data projects either succeed or fall apart. Professionals call this unified record the “golden record.” It is the canonical version of a property’s identity that all downstream analysis depends on.
Pro Tip: Before you run any analysis, audit your data sources for overlap. A property appearing in three databases with three slightly different addresses will corrupt your clustering models and skew your valuation outputs.
Which data mining techniques are commonly applied in real estate?
Five core techniques dominate real estate data mining: outlier detection, classification, association rule mining, clustering, and predictive modeling. Each one answers a different question about your data.
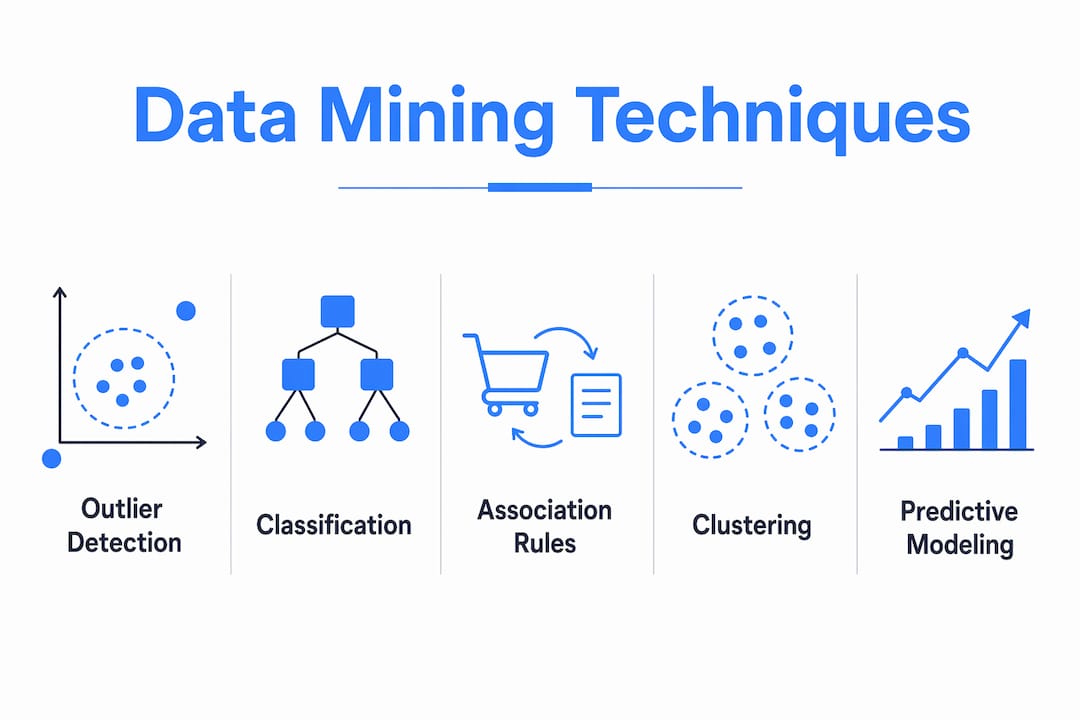
| Technique | What it does | Real estate application |
|---|---|---|
| Outlier detection | Flags values that deviate from the norm | Identifies mispriced listings or fraudulent transactions |
| Classification | Assigns records to predefined categories | Segments properties by risk level or seller motivation |
| Association rule mining | Finds co-occurring variables | Reveals which property features correlate with faster sales |
| Clustering | Groups similar records without predefined labels | Segments neighborhoods or buyer profiles by behavior |
| Predictive modeling | Forecasts future values using historical patterns | Estimates market value, time-on-market, or default probability |
Predictive modeling is where machine learning earns its reputation. Gradient boosting models like HistGradientBoostingRegressor capture non-linear relationships in housing prices that traditional regression misses entirely. A 2026 MDPI study applying this algorithm to Madrid housing data achieved an R² of 0.6877, meaning the model explained nearly 69% of price variance using spatial and structural features alone. That level of accuracy outperforms most traditional appraisal methods on comparable datasets.
Clustering deserves special attention for wholesalers. When you cluster distressed property records by neighborhood, property age, lien status, and owner occupancy, you get natural lead segments. Each cluster behaves differently. Probate leads in one cluster respond to different messaging than tax delinquent leads in another. Mining reveals those segments. Your outreach strategy then matches the pattern.
Pro Tip: Start with clustering before you build predictive models. Clusters reveal natural groupings in your data that improve model accuracy when used as input features. Skipping this step is one of the most common mistakes analysts make on their first real estate mining project.
How does geocoding and spatial analysis enhance real estate data mining?
Geocoding converts a property address into geographic coordinates, latitude and longitude, that spatial models can use as features. This step is not optional. Incorporating geospatial features is methodologically critical for accurate real estate modeling, not a nice-to-have addition.
Here is why location accuracy dominates model performance:
- A property geocoded to the wrong block gets assigned the wrong neighborhood quality score
- Proximity to schools, transit, and amenities shifts by hundreds of meters when coordinates are off
- Flood zone classification, zoning category, and crime index all depend on precise coordinates
- Spatial segmentation, dividing a market into micro-zones, requires accurate anchoring to work
Geocoding errors dominate model error in machine learning valuation because location inaccuracies shift properties into incorrect neighborhood contexts. A house that belongs in a high-demand school district gets modeled as if it sits in a lower-performing one. The valuation drops. The investment decision changes. The error compounds downstream.
Spatial analysis goes beyond simple coordinates. Analysts build features like distance to the nearest highway, walkability score, and density of comparable sales within a half-mile radius. These features feed directly into gradient boosting and random forest models, improving prediction accuracy on both price and time-on-market. For investors targeting specific zip codes or census tracts, spatial segmentation also allows you to build separate models for each micro-market rather than forcing one model to explain an entire metro area.
What are practical workflows and challenges in real estate data mining?
A working real estate data mining workflow follows four stages: collection, aggregation, analysis, and deployment. Each stage has specific failure points you need to anticipate.
-
Collection. Use RPA tools and web scraping to pull listing data from platforms like Idealista, Fotocasa, county assessor portals, and MLS feeds. Set refresh intervals based on market velocity. A fast-moving market needs daily pulls. A slower rural market can tolerate weekly updates.
-
Aggregation. This is where most projects break down. Data aggregation workflows require standardizing and de-duplicating multi-source property records, then creating golden records with confidence scores and audit trails. Source-priority rules determine which field value wins when two sources conflict. Recency alone is not enough. A recently scraped listing with a typo in the address should not override a validated county record from six months ago.
-
Analysis. Apply the appropriate technique to your question. Outlier detection for pricing anomalies. Clustering for lead segmentation. Predictive modeling for valuation or default probability. Each technique requires clean input data. Garbage in, garbage out is not a cliché here. It is a precise description of what happens when you skip step two.
-
Deployment. Models need monitoring. Entity resolution — matching multiple listings to a single property with confidence scoring — prevents valuation errors and model drift over time. Treating unstructured data as evidence with provenance and confidence scoring maintains trust and auditability in your property profiles. When a model starts drifting, you need lineage records to trace the source of the error.
The hidden costs of free property data are real. Free sources often lack the standardization and update frequency that reliable mining requires. Investors who build workflows on free data alone frequently discover their models are training on stale or incomplete records, which produces confident-sounding predictions that are simply wrong.
Key takeaways
Real estate data mining delivers its highest value when geocoding accuracy, entity resolution, and structured aggregation workflows are treated as foundational requirements, not afterthoughts.
| Point | Details |
|---|---|
| Data mining vs. analytics | Mining discovers hidden patterns; analytics interprets known data. Both serve different strategic purposes. |
| Golden record creation | Standardize and de-duplicate multi-source records before any analysis to prevent model errors. |
| Geocoding accuracy | Location inaccuracies shift properties into wrong neighborhood contexts, corrupting valuation models. |
| Clustering for lead segmentation | Group distressed properties by behavior before building predictive models to improve targeting precision. |
| Machine learning outperforms tradition | Gradient boosting models explain nearly 69% of price variance, outperforming traditional appraisal on comparable data. |
Why geocoding and entity resolution are where I focus first
I have reviewed enough real estate data projects to say this with confidence: the majority of failed analyses trace back to two problems. Bad geocoding and unresolved duplicate records. Not the algorithm. Not the feature selection. The foundation.
Most investors and analysts want to jump straight to the model. They want the R² score and the predicted ARV. I understand the impulse. But a model built on mismatched property records is not a valuation tool. It is a confidence machine that produces wrong answers with high precision.
A unified canonical property record with confidence scoring and lineage is a genuine competitive advantage. The investors who build that infrastructure, even at small scale, make better decisions than those who rely on raw list pulls. I have seen wholesalers with 500 clean, well-segmented records outperform competitors working from 5,000 messy ones.
The emerging trend worth watching is text mining on listing descriptions and seller communications. Sentiment signals in how a property is described, words like “motivated,” “as-is,” or “estate sale,” correlate with seller flexibility and time-on-market. Combining those signals with structured transaction data is where the next generation of real estate analytics is heading. If you are building a data practice now, start adding unstructured text fields to your models. The AI cold call simulator tools emerging in 2026 are already starting to incorporate these signals into outreach prioritization.
The bottom line: precision in your data infrastructure pays more than sophistication in your algorithms. Get the foundation right first.
— Dave
Put your data mining insights to work on every call
Data mining tells you who to call and why they might sell. What it cannot do is train you to handle the conversation when you get them on the phone. That is where ClosersLeague comes in.
ClosersLeague is an AI-powered cold calling training platform built specifically for real estate investors and wholesalers. Once your data mining workflow surfaces a foreclosure lead, a probate record, or a tax delinquent property, you need to be ready to convert that conversation. ClosersLeague’s cold calling practice tool uses AI roleplay to simulate real seller objections across every distressed seller type. Stop winging it. Start drilling. Your data found the lead. Now close it.
FAQ
What is real estate data mining in simple terms?
Real estate data mining is the process of analyzing large property datasets using statistical and machine learning methods to uncover patterns that inform investment and valuation decisions. It goes beyond basic reporting by discovering relationships in data that are not immediately obvious.
How is data mining different from real estate analytics?
Data mining is exploratory and discovers hidden patterns in raw data, while analytics interprets existing datasets to support known questions. Mining finds what you did not know to look for; analytics explains what you already suspect.
What data sources are used in real estate data mining?
Common sources include listing platforms like Idealista and Fotocasa, county assessor records, MLS feeds, tax databases, and demographic data providers. Combining structured transaction data with unstructured listing descriptions produces the most complete property profiles.
Why does geocoding matter so much in real estate data mining?
Geocoding errors shift properties into incorrect neighborhood contexts, which corrupts spatial features and degrades model accuracy. A 2026 MDPI study confirmed that location data accuracy is one of the dominant factors in predictive real estate valuation model performance.
What machine learning models work best for real estate valuation?
Gradient boosting models, including HistGradientBoostingRegressor, consistently outperform traditional regression on housing price prediction because they capture non-linear relationships between property features and market value. A 2026 study on Madrid housing data achieved an R² of 0.6877 using this approach.